目錄:
-- CLIP簡介
-- CLIP的基本架構
-- 圖解CLIP的運算過程
-- CLIP開源程式的挖礦流程
-- 結語
2.1 CLIP簡介
AIGC可生成的內容形式,包含文本(文句)、圖像、音訊和視頻。它能夠將文本中的語言符號資訊或知識,與視覺中視覺化的資訊(或知識)建立出對應的關聯。兩者互相加強,形成圖文並茂的景象,激發人腦更多想像,擴大人們的思維空間。
其中,最基礎的就是文本(Text)與圖像(Image)之間的知識關聯。那麼,在本篇裡,就來介紹文本與圖像的關聯,並以CLIP模型為例,深入介紹多模態AIGC模型的幕後架構,例如潛藏空間(Latent space)就是其中的關鍵性機制。在2020年,OpenAI團隊提出了CLIP,它是典型的多模態(Multi-modal)機器學習模型。OpenAI從互聯網上找到大量的文本(Text)與圖像(Image)的配對,可以用來訓練CLIP模型,然後讓CLIP進行其預測任務,即是輸入一張圖像,然後預測出那一個文本與它是配對的。
CLIP的目標是透過大量圖片及文字描述,建立兩者間的對應關係。其做法是利用ResNet50等來萃取圖像的特徵,並映射到潛藏空間。也就是將圖像編碼成為潛藏空間向量。同時,也利用Transformer萃取與圖像相配對文句的特徵,並將文句編碼成為潛藏空間向量。最後經由模型訓練來逐漸提高兩個向量的相似度。換句話說,CLIP能將圖像和文句映射到同一個潛藏空間,因此可以迅速計算圖像與文句的相似度。
CLIP模型學習整個文句與其對應的圖像之間的關係。當我們在整個文句上訓練時,模型可以學到更多的潛在的東西,並在圖像和文句之間找到一些規律。值得留意的是,在訓練CLIP模型時,我們輸入的是整個文句,而不是像貓、狗、汽車、電影等單一類別而已。
2.2 CLIP的基本架構
CLIP的核心設計概念是,把各文句和影像對應到潛藏空裡的一個點(以向量表示)。針對每一個文句和圖像都會提取其特徵,並映射到這個隱空間裡的某一點。然後經由矩陣運算,來估計它們之間的相似度(圖-1)。
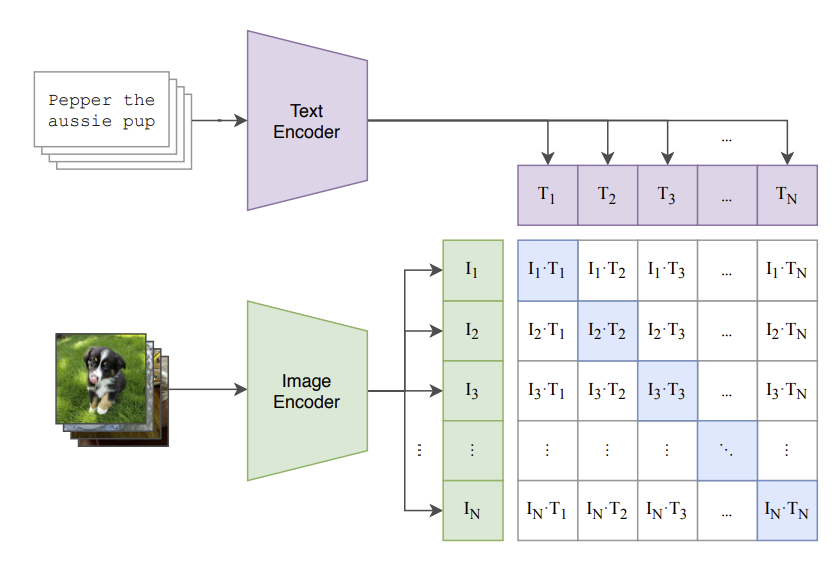
(图-1:https://openai.com/research/clip)
在訓練CLIP模型的過程中,會不斷調整各點的位置(在潛藏空間裡),以表達出它們之間的相似度。CLIP在整合文句與圖像兩種模態上有突破性的表現。一旦訓練完成之後,就可以對新圖像進行預測了,亦即預測出那一個文本與它是配對的。例如,輸入一張新圖像,經由圖像編碼器(如ResNet50)來提取這張圖像的特徵,然後映射到潛藏空間裡的一個新的點。
然後經由矩陣運算,即可預測出它與我們所給的一些文句的相似度,就可以得到預測值了。此外,CLIP也能輸入描述文句來找到相對應的圖像。
2.3 圖解CLIP的運算過程
以中藥材的CLIP為例,例如,有4張中藥材的圖像,以及其對映的文本(提詞),如下圖: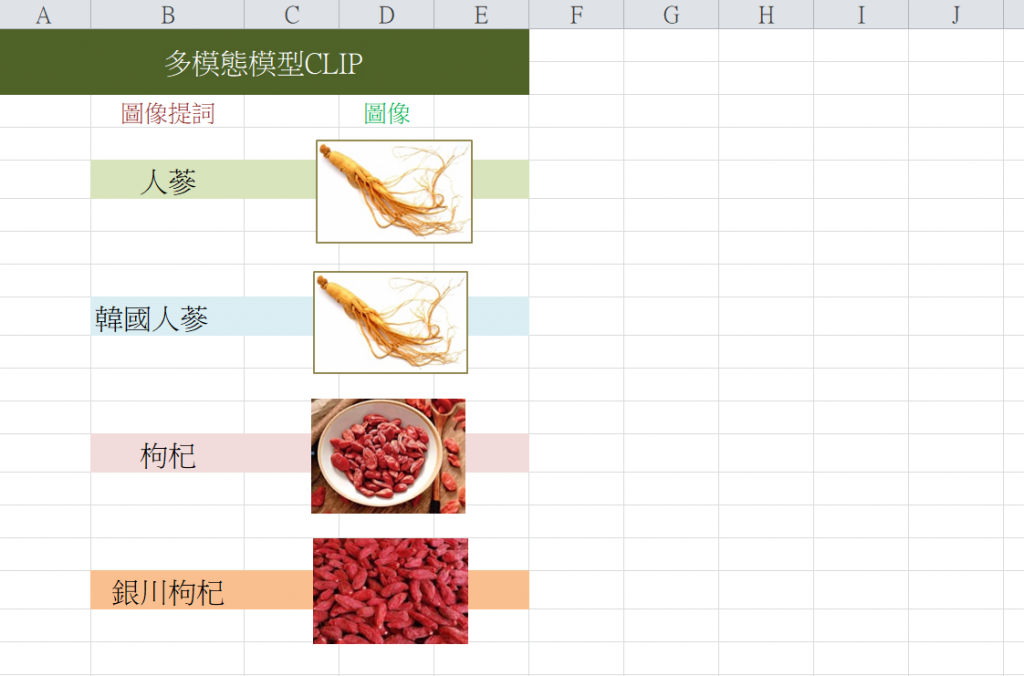
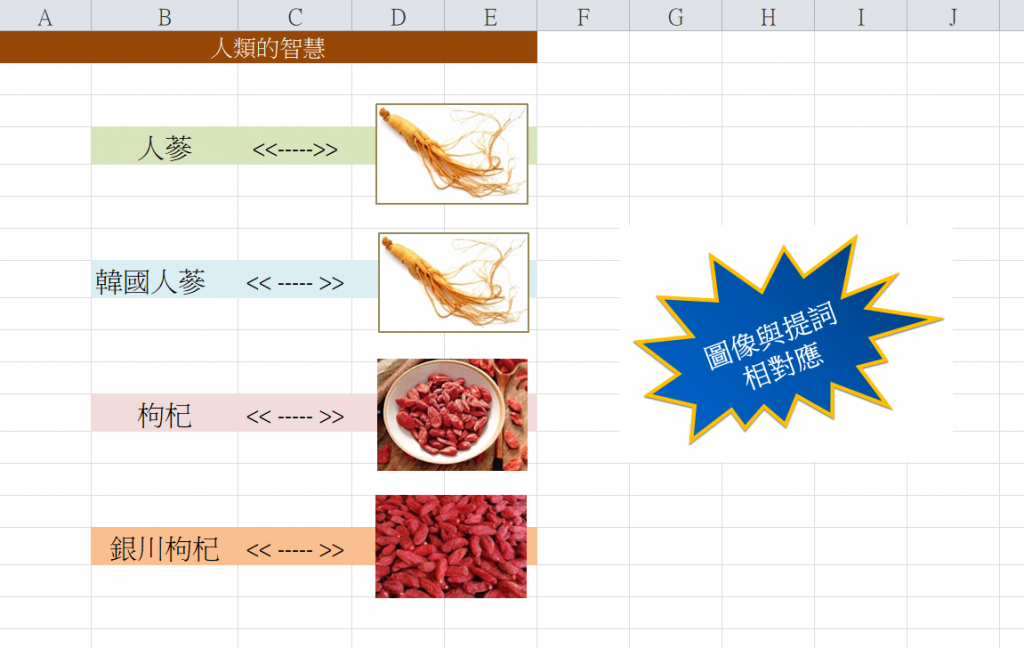
CLIP從互聯網取得人類的智慧(即文本與圖像的對應關係):
然後,CLIP使用ResNet50等來幫助提取個圖像的特徵,然後將各圖像(隨意)對映到潛藏空間(即數學裡的歐式空間)的點。同時,使用Transformer來幫助提取個文本的特徵,然後將各文本(隨意)對映到潛藏空間的點。如下圖: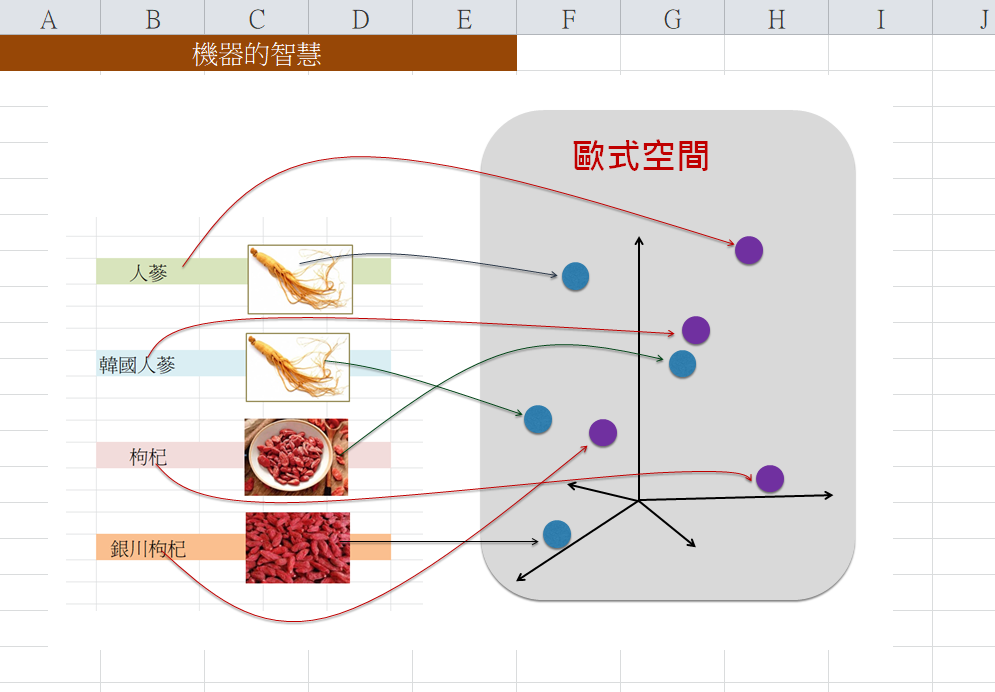
<<展開訓練>>
接著,進行訓練,在其過程中逐漸地修正CLIP模型裡的參數(即weight和bias值),也就是逐漸地調整潛藏空間裡各點的位置(座標),來呈現出這些點之間的相似性(Similarity)。例如,在潛藏空間裡,愈相似的點,就會愈相互靠近,如下圖:
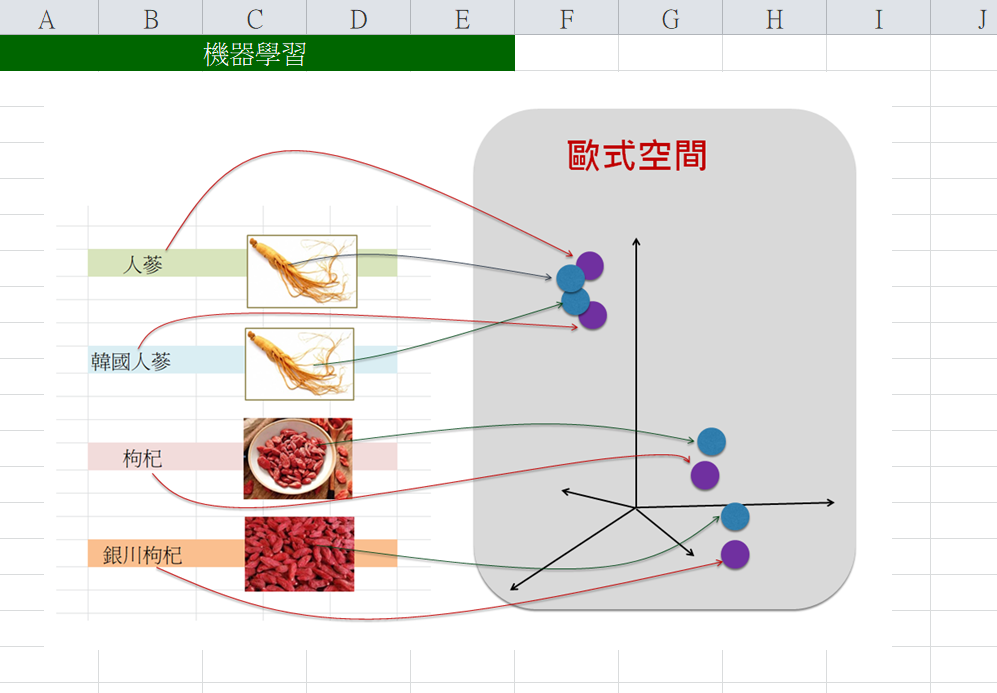
以上訓練完成了。其智慧表達於模型裡的參數(即weight和bias)值裡。
<<預測(一):從圖像找文本>>
例如,拿來一張新圖像輸入給CLIP,它就(要求ResNet50等)來幫忙提取這新圖像的特徵,並依據其所訓練出來的參數(即weight和bias)值,而計算(對映)出整潛藏空間裡這個新點的位置(座標),呈現如下:
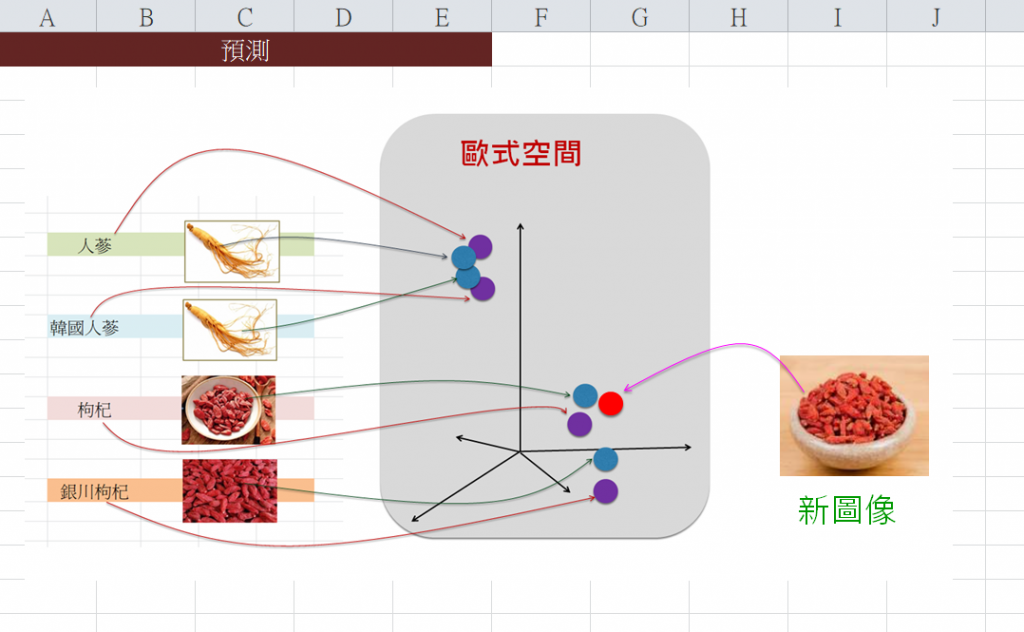
接著,計算出這點與其他各點之相似度,然後挑出相似性最高的文本是:<枸杞>。如下圖:
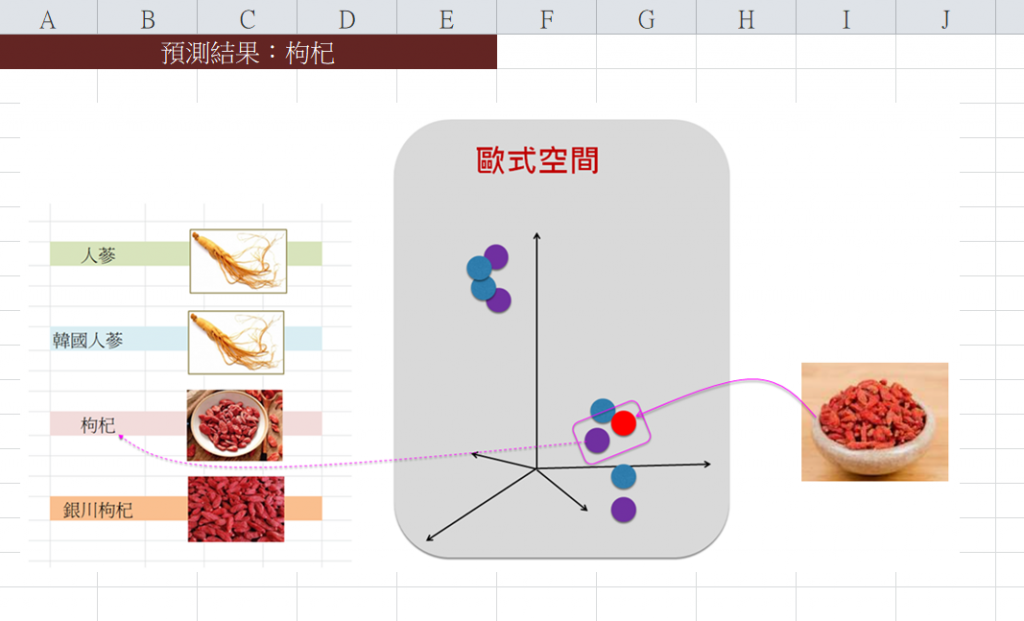
<<預測(二):從文本找圖像>>
例如,拿來一個新文句輸入給CLIP,它就(要求Transformer等)來幫忙提取這新文句的特徵,並依據其所訓練出來的參數(即weight和bias)值,而計算(對映)出整潛藏空間裡這個新點的位置(座標),呈現如下:
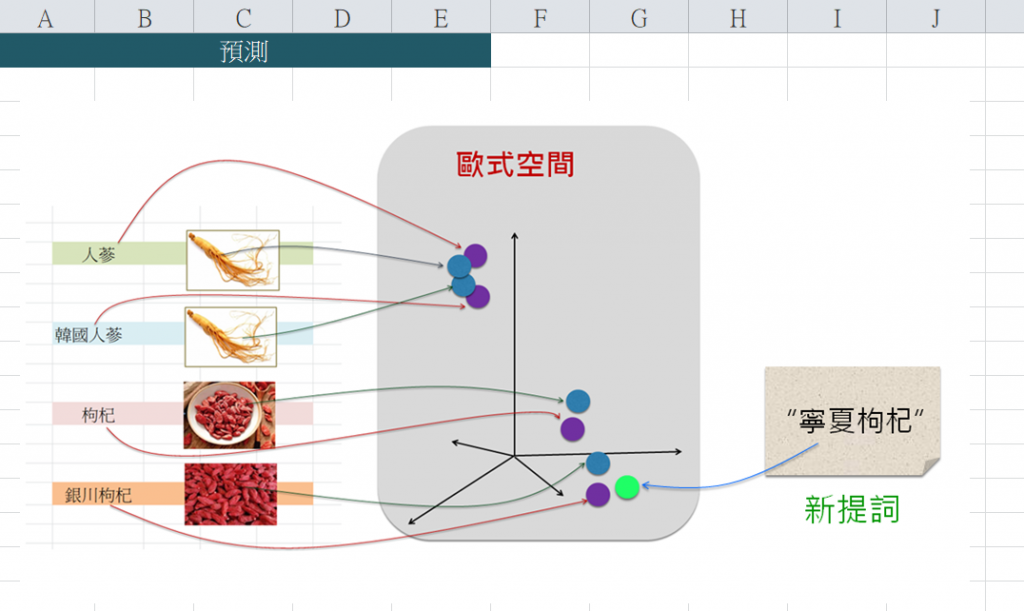
接著,計算出這點與其他各點之相似度,然後挑出相似性最高的圖像,如下:
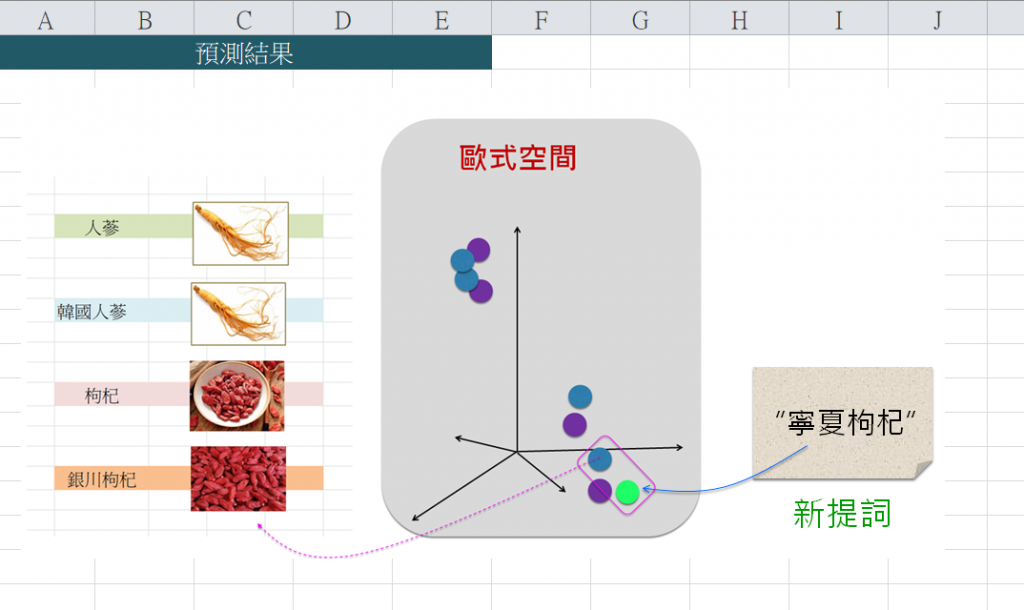
於是,取出這張圖像:

2.4 CLIP開源程式的挖礦流程
Step-1. 下載源碼,切入主模型:CLIPModel
首先,從這個網頁下載CLIP開源程式碼:
https://github.com/moein-shariatnia/OpenAI-CLIP
然後,切入主模型:CLIPModel。一開始,先不訓練主模型,只要先誕生(創建)主模型,檢查看看我們的Python環境裡,是否已經有具備CLIP所需要的各項套件。例如,我的環境並沒有安裝timm套件。於是就動手安裝它了,但是執行時卻發生版本的問題,於是我就拿ResNet50來替換timm,就可以了。
本階段的目標是:檢驗這Clip模型所用到的各種套件,所以先把Clip模型抓到我們自己的Python IDLE來看看,能否順利建立Clip的模型物件(Object)。也就是這一行指令是正確的:
model = CLIPModel()
於是,下載了CLIP開源程式碼,並刪除不必要程式,就得到簡化的程式碼:
# clip_basic_001.py
接著,就在我自己的Python IDLE環境裡,來執行這程式。此程式執行時,順利輸出:

這是非常關鍵的第一步驟。它檢驗了我的訓練環境。
Step-2. 把資料輸入給CLIP模型
接下來,就進入第2步驟:把資料輸入剛才建立的模型物件。這目的在於檢驗訓練資料的格式。
Step-2.1 由於CLIP必須輸入 Text和Image。
而Image最有名的預訓練模型就是Resnet50,其Image格式為:224 x 224。所以我找來一堆224 x 224的<中藥材>圖像(JPG格式),共4張。並且放置於c:/oopc/m_clip_data/train/目錄區裡,如下:

Step-2.2 審視文句(Text)資料的輸入。
由於CLIP是基於Transformer基礎模型,其Text幾乎都是Transformer的標準,於是我4張圖像的對應Text來輸入。例如:
sequences = [
"人蔘",
"韓國人蔘",
"枸杞",
"銀川枸杞"
]
這是此步驟(第2.2步驟)的目標,即是這行指令:
out = model( batch )
在此,檢驗看看是否能順利輸入給CLIP模型,而且模型又能順利地輸出結果。於是,我就拿剛才所準備的資料集來輸入看看。於是,就來微調一下程式碼:
# clip_basic_002.py
此程式執行時,輸出:

在這步驟裡,先不必計較輸出結果的涵意,只要能順利輸入資料和輸出結果,就已正確檢驗了訓練資料的格式了。
Step-3. 添加Loss函數及Optimizer,並訓練1回合
現在進入第3步驟,其目標是:基於Step-2的暫時性資料輸入,添加損失(Loss)函數,來展開檢驗<訓練步驟>的程式碼,目標只訓練一回合。亦即,在這第3步驟裡,將要檢驗<訓練步驟>的程式碼,其目標只訓練一回合,輸出一項Loss值。於是,增添訓練部分的程式碼,如下:
執行時,輸出:

Step-4. 訓練多個回合,觀察loss值是否持續下降
在這第4步驟裡,將訓練更多個回合,仔細觀察Loss值是否持續下降。於是稍微調整程式碼,如下:
此程式執行時,輸出:
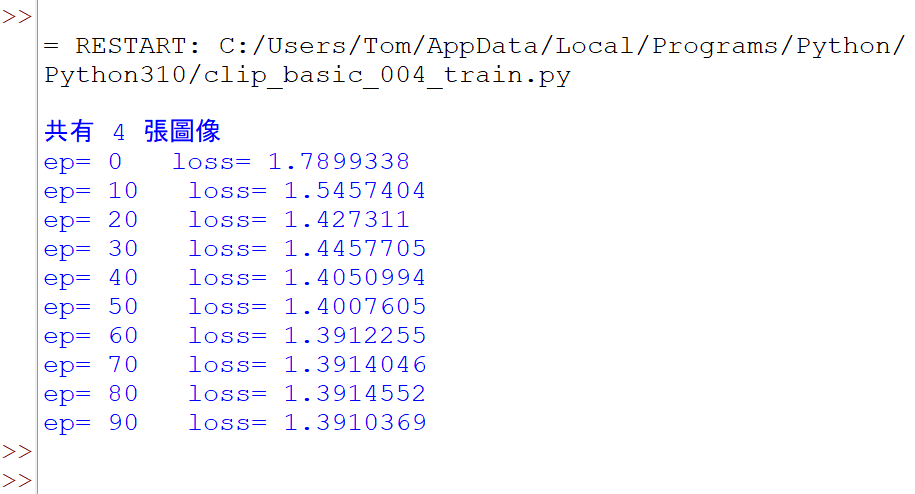
這顯示出Loss會逐漸下降了。
2.5 結語
在本篇(第2篇)裡,以CLIP為範例來展示如何從GitHub網頁上挖礦(淘金),免費獲取大模型的開源程式碼,並立即進行關鍵性的4步驟,進行基本要素的檢驗。
一旦通過了這4項檢驗,就能進入正式的訓練流程,包括準備完整的訓練資料、測試資料,以及各種應用場景的規劃了。
明天(第3篇)將繼續說明進入正式訓練流程的各項工作。感謝您的閱讀。

